Drawing with CUDA: Lines and Circles

Photo by Derek Thomson on Unsplash
Drawing with CUDA: lines and circles⌗
Pre-requisites⌗
- Completed the previous tutorial here
What is Parallel Computing⌗
At a high level, parallel computing is the simultenous use of multiple computing resources to solve a computational problem. The problem is broken into separate parts that can be solved concurrently.
Parallel Computing with CUDA⌗
CUDA is Nvidia’s parallel computing platform. CUDA has interfaces in many programming languages e.g. C++, Fortan, Python etc.
For this post, we will be focussing on CUDA for C++.
CUDA C++ Syntax and Terminology⌗
Background Information
- Host refers to the CPU and Device refers to the GPU, we can have multiple Devices serving one Host
- Functions with the
__global__are functions called from the Host to be executed on the Device - All parameters MUST be pointers as we are refering to variables on the device
- Host pointers point to host memory
- Device pointers point to device memory
- You can’t derefrence (Access values) Host pointers on the Device and vice versa.
- Use
cudaMalloc(),cudaFree(),cudaMemcpy()to manage device memory
Each parallel invocation of our function is referred to as a block. The set of blocks is referred to as a grid
The syntax of kernel execution configuration is as follows <<< M , T >>>
-
Which indicate that a kernel launches with a grid of M thread
blocks. Each thread block has T parallelthreads. -
example:
// 1 thread block with 256 parallel threads vector_add <<< 1 , 256 >>> (d_out, d_a, d_b, N); -
extended execution configuration is
<<< Dg, Db, Ns, S >>>:Dgis of typedim3(see dim3) and specifies the dimension and size of the grid, such thatDg.x * Dg.y * Dg.zequals the number of blocks being launched;Dbis of typedim3(see dim3) and specifies the dimension and size of each block, such thatDb.x * Db.y * Db.zequals the number of threads per block;Nsis of typesize_tand specifies the number of bytes in shared memory that is dynamically allocated per block for this call in addition to the statically allocated memory; this dynamically allocated memory is used by any of the variables declared as an external array as mentioned in__shared__Nsis an optional argument which defaults to 0;- shared memory is block level i.e only threads in the same block can access it
Sis of typecudaStream_tand specifies the associated streamSis an optional argument which defaults to 0.
-
Dim3 note:
Dim3is used to manage how you want to access blocks and grids i.e you access them in a 1 Dimensional, 2 Dimensional or 3 Dimensional manner- This is useful depending on the kind of data you are passing in, so if we are dealing with an image, we can specify
DgandDbas:
const dim3 Db(8, 8); const dim3 Dg(iDivUp(out_width,blockDim.x), iDivUp(out_height,blockDim.y));dim3can take up to 3 parameters, any unitialized parameters will default to 1- so in our example Db is an
[8,8,1]block (num threads in this block is 64 = 8 * 8 * 1) and Dg is a[out_width/blockDim.x, out_height/blockDim.y, 1]grid where the number of blocks is (out_width/blockDim.x * out_height/blockDim.y * 1) - to access dimensional indexes, use .x, .y, .z e.g blockDim.x, blockDim.y, blockDim.z
- it seems convetional to declare Db yourself and then have Dg be the number of values you want to process (in a specified dimension), N, divided by Db
-
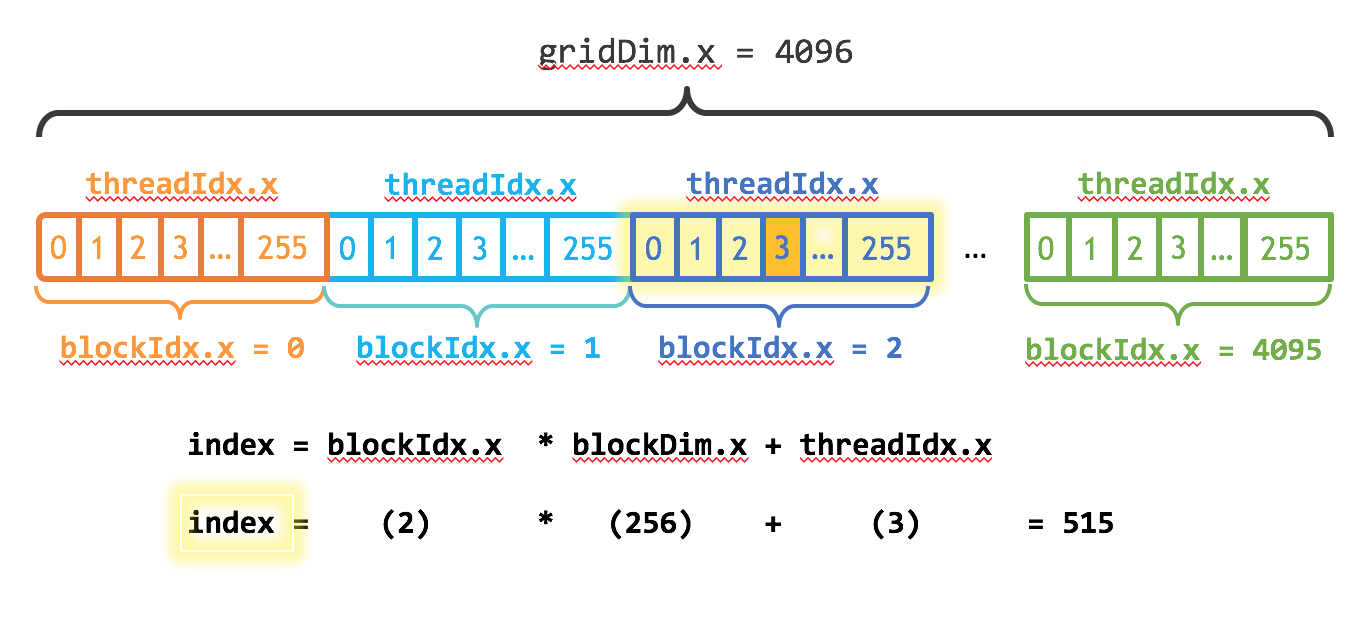
Such index can be computed as follow
// tid, our global unique thread ID int tid = (blockIdx.x * blockDim.x) + threadIdx.x; // think of this like a 2d array arranged sequentially // so to get the thread ID for the thread id at // block 2, thread 50; where each block is of size 256 // tid = (2 * 256) + 50 // tid = 562- blockIdx.x contains the index of the current thread block in the grid, use this index if you want to compute using parallel blocks
- blockDim.x contains the number of threads in the bloc
- threadIdx.x contains the index of the current thread within its block, use this index if you want to compute using parallel threads
- tid is extremely important as it contians the index allowing us to used parallel blocks and threads
-
A good rule of thumb: With T threads per thread block and N elements to process, we need at least N/T thread blocks to have a total of X threads. To assign a thread to a specific element, we need to know a unique index for each thread.
// example with 256 thread blocksize i.e T = 256 int blockSize = 256; int numBlocks = (N + blockSize - 1) / blockSize; add<<<numBlocks, blockSize>>>(N, a, b);
The following is a comparison between sequential execution (for loop add over 2 vectors) versus parallel execution (use GPU threads to add all at once)
Normal Execution:
#define VECTOR_LENGTH 100000
int main ()
{
int *vecA;
int *vecB;
int *vecC;
int size = VECTOR_LENGTH * sizeof(int);
vecA = (int *)malloc(size);
vecB = (int *)malloc(size);
vecC = (int *)malloc(size);
// fill vectors a and b with random integers
random_ints(vecA, VECTOR_LENGTH);
random_ints(vecB, VECTOR_LENGTH);
for (int x = 0; x < VECTOR_LENGTH; x++) {
vecC[x] = vecA[x] + vecB[x];
}
// clean up memory
free(vecA);
free(vecB);
free(vecC);
return 0;
}
Parallel Execution:
#define VECTOR_LENGTH 100000
// gpuVectorAdd
__global__ void gpuVectorAdd(
int* vecA,
int* vecB,
int* vecC,
int vecLength
)
{
const int x = blockIdx.x * blockDim.x + threadIdx.x;
// to prevent overunning our vectors
if( x >= vecLength)
return;
vecC[x] = vecA[x] + vecB[x];
}
int main ()
{
int *vecA;
int *vecB;
int *vecC;
int *d_a;
int *d_b;
int *d_c;
int size = VECTOR_LENGTH * sizeof(int);
// declare our memory size
cudaMalloc((void **)&d_A, size);
cudaMalloc((void **)&d_B, size);
cudaMalloc((void **)&d_C, size);
vecA = (int *)malloc(size);
vecB = (int *)malloc(size);
vecC = (int *)malloc(size);
// fill vectors a and b with random integers
random_ints(vecA, VECTOR_LENGTH);
random_ints(vecB, VECTOR_LENGTH);
// copy input vectors host to gpu memory
cudaMemcpy(d_a, vecA, size, cudaMemcpyHostToDevice);
cudaMemcpy(d_b, vecB, size, cudaMemcpyHostToDevice);
// define kernel launch parameters
const dim3 blockDim(32);
const dim3 gridDim(iDivUp(VECTOR_LENGTH, blockDim.x));
// launch the add kernel
gpuVectorAdd<<<gridDim, blockDim>>>(
vecA,
vecB,
vecC,
VECTOR_LENGTH
);
// copy results from gpu memory to host memory
cudaMemcpy(vecC, d_C, size, cudaMemcpyDeviceToHost);
// clean up host memory
free(vecA);
free(vecB);
free(vecC);
// clean up device memory
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
return 0;
}
CUDA in Action⌗
One thing to remember is that when you are in your parallelized function, you are running in a loop, so use your given thread index to do the thing you would have done in a loop form
If you completed the previous tutorials you would have seen poseNet.cu and poseNet.cuh. These were used to draw the resultant pose points and lines that our model provided as output.
Lets go through the code and explain how it works (I have cut out some code for brevity and left in the pertinent parts)
-
poseNet.cuh#ifndef __POSE_NET_PREPROCESSING_H__ #define __POSE_NET_PREPROCESSING_H__ #include "Tensor.h" #include <jetson-utils/cudaUtility.h> ... __global__ void gpuDrawCircle( float4* output, const int out_width, const int out_height, const int center_x, const int center_y, const int radius ); __global__ void gpuDrawLine( float4* output, const int out_width, const int out_height, const float x0, const float y0, const float x1, const float y1 ); cudaError_t cudaDrawPose( float4* output, uint32_t out_width, uint32_t out_height, jetsoncam::Tensor<int> topology, jetsoncam::Tensor<int> object_counts, jetsoncam::Tensor<int> objects, jetsoncam::Tensor<float> normalized_peaks, cudaStream_t stream ); #endif.cuhfiles are header files for cuda, they function similarly to regular C++ header files i.e we define our function signatures here- notice the 2 functions with the
__global__are functions intended to be executed on the GPU, while the function at the bottom will be executed on the host
-
poseNet.cu#include "poseNet.cuh" #include "Tensor.h" #include <jetson-utils/cudaUtility.h> #include <cstdlib> #include <cmath> // gpuDrawCircle __global__ void gpuDrawCircle( float4* output, const int out_width, const int out_height, const int center_x, const int center_y, const int radius ) { const int x = blockIdx.x * blockDim.x + threadIdx.x; const int y = blockIdx.y * blockDim.y + threadIdx.y; if( x >= out_width || y >= out_height ) return; // if x,y is in the circle draw it if ((x - center_x)*(x - center_x) + (y - center_y)*(y - center_y) < (radius * radius)) { const float4 color = make_float4(0.0f, 0.0f, 255.0f, 255.0f); output[y * out_width + x] = color; } } // gpuDrawLine __global__ void gpuDrawLine( float4* output, const int out_width, const int out_height, const float x0, const float y0, const float x1, const float y1 ) { const int x = blockIdx.x * blockDim.x + threadIdx.x; const int y = blockIdx.y * blockDim.y + threadIdx.y; if( x >= out_width || y >= out_height ) return; float AB = std::sqrt((x1-x0) * (x1-x0) + (y1-y0) * (y1-y0)); float AP = std::sqrt((x-x0) * (x-x0) + (y-y0) * (y-y0)); float PB = std::sqrt((x1-x) * (x1-x) + (y1-y) * (y1-y)); // adjust threshold to make the line thicker const float threshold = 0.1f; if (std::fabs(AB - (AP + PB)) <= threshold) { const float4 color = make_float4(0.0f, 0.0f, 255.0f, 255.0f); output[y * out_width + x] = color; } } // cudaPreImageNet cudaError_t cudaDrawPose( float4* output, uint32_t out_width, uint32_t out_height, jetsoncam::Tensor<int> topology, jetsoncam::Tensor<int> object_counts, jetsoncam::Tensor<int> objects, jetsoncam::Tensor<float> normalized_peaks, cudaStream_t stream ) { if( !output ) return cudaErrorInvalidDevicePointer; if( out_width == 0 || out_height == 0 ) return cudaErrorInvalidValue; int K = topology.size(0); int count = object_counts.retrieve({0}); //printf("count: %d\n", count); //printf("K: %d\n", K); //printf("output image width %u, height %u\n", out_width, out_height); // launch kernel const dim3 blockDim(8, 8); const dim3 gridDim(iDivUp(out_height,blockDim.x), iDivUp(out_height,blockDim.y)); for(int i = 0; i < count; i++) { int C = objects.size(2); for (int j = 0; j < C; j++) { int k = objects.retrieve({0,i,j}); if (k >= 0) { float x = normalized_peaks.retrieve({0,j,k,1}) * float(out_width); float y = normalized_peaks.retrieve({0,j,k,0}) * float(out_height); // DRAW x,y to a circle with color gpuDrawCircle<<<gridDim, blockDim, 0, stream>>>( output, out_width, out_height, (int) x, (int) y, 5 ); } } for (int k = 0; k < K; k++) { int c_a = topology.retrieve({k,2}); int c_b = topology.retrieve({k,3}); int obj_c_a = objects.retrieve({0,i,c_a}); int obj_c_b = objects.retrieve({0,i,c_b}); if (obj_c_a >= 0 && obj_c_b >= 0) { float x0 = normalized_peaks.retrieve({0,c_a,obj_c_a,1}) * float(out_width); float y0 = normalized_peaks.retrieve({0,c_a,obj_c_a,0}) * float(out_height); float x1 = normalized_peaks.retrieve({0,c_b,obj_c_b,1}) * float(out_width); float y1 = normalized_peaks.retrieve({0,c_b,obj_c_b,0}) * float(out_height); // printf("gpuDrawLine-> obj_c_a: %d, obj_c_b: %d, x0: %f, y0: %f, x1: %f, y1: %f\n",obj_c_a, obj_c_b, x0, y0, x1, y1); // DRAW line from x0,y0 to x1,y1 gpuDrawLine<<<gridDim, blockDim, 0, stream>>>( output, out_width, out_height, x0, y0, x1, y1 ); } } } return CUDA(cudaGetLastError()); } ...- The function
cudaDrawPoseis called fromposeNet.cpp. cudaDrawPoselaunches the drawing kernels on the GPU using thegpuDrawLine<<<gridDim, blockDim, 0, stream>>>(...)or thegpuDrawCircle<<<gridDim, blockDim, 0, stream>>>(...)calls.- Notice how we specify the number of blocks and number of threads per block in 2-Dimensions, since we are working on an image.
- we get our 2-Dimensional thread indexes (x,y) by using:
const int x = blockIdx.x * blockDim.x + threadIdx.x; const int y = blockIdx.y * blockDim.y + threadIdx.y;- we also check to make sure that our 2-Dimensional thread indexes are not out of the bounds of our image, the reason is the number of threads we declare may not exactly match the number of pixels in our image (e.g blocksize limits):
if( x >= out_width || y >= out_height ) return; - The function
You have seen this before, but it was included for contexts sake, this piece of command is added to our CMakeLists.txt so we can compile our CUDA code:
# we have to compile CUDA libs separately
CUDA_COMPILE(posenet_cuda_o src/poseNet.cu)
add_executable(imagetaker_posenet
...
${posenet_cuda_o}
...
)
- NOTE: the
CUDA_COMPILEand the${posenet_cuda_o}
Parallel Computing benefits⌗
Using the GPU to draw is extremely helpful as we can Draw on all pixels at Once!
So when if we want to draw 10 cirles, we dont need to do a 10xWxH loop over each pixel, we can instead do a 10x loop! In fact, those who are more experienced with CUDA can draw all 10 images in a single pass!
Parallel computing has greatly helped Artificial Intelligence research as costly operations, e.g convolutions, can be parallelized and training speed increased greatly.
If you are planning on doing any real time inferencing, especially with high dimensional data structures like images or videos. It is extremely important to know how to leverage GPU’s on your device.
Thank you for making it to the end of this most, if you have any questions or concerns, leave a comment!
Links to source code⌗
Full source code available on GitHub